Redis作为一个使用场景很高的NoSQL数据库,支持了较为丰富的数据类型,相比于其他关系型数据库在性能方面优势明显。互联网公司通常更加倾向于将一些热点数据放入Redis中来承载高吞吐量的访问。
单机Redis在普通的服务器上通常ops上限在5w左右,开启pipeline的情况下在20-30w左右。对于大多数中小公司来说,通常单机的Redis已经足够,最多根据不同业务分散到多台Redis。
为什么需要集群
- Redis单线程特性,多请求顺序执行,单个耗时的操作会阻塞后续的操作
- 单机内存有限
- 某些特殊业务,带宽压力较大
- 单点问题,缺乏高可用性
- 不能动态扩容
Redis集群的目标就是为了实现高可用性,避免性能瓶颈,可动态扩容,易于做监控告警。
三种主流的集群解决方案
客户端静态分片
通常需要 smart-client 支持,在业务程序端根据预先设置的路由规则进行分片,从而实现对多个redis实例的分布式访问。
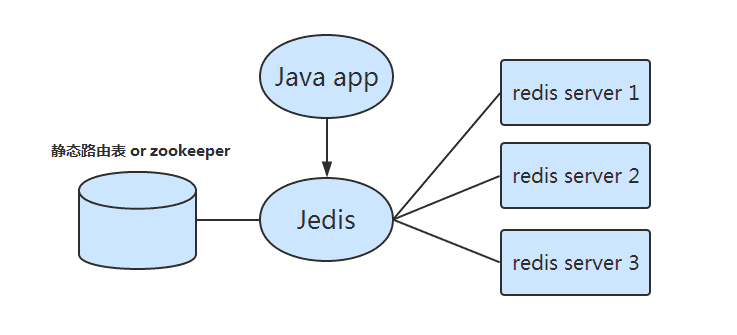
鉴于redis本身的高性能,并且有一些设计良好的第三方库,例如java开发者可以使用jedis,所以很多小公司使用此方案。
优点: 相比于使用代理,减少了一层网络传输的消耗,效率较高。
缺点: 当redis实例需要扩容或切换的情况下,需要修改业务端的程序,较为麻烦。并且需 要维护各个语言的客户端版本,如果要升级客户端成本也会比较高。出现故障时难以及时定位问题。(有些smart-client借助于zookeeper维护客户端访问redis实例的一致性)
Proxy分片
通过统一的代理程序访问多个redis实例,比如业内曾广泛使用的 twemproxy 以及 豌豆荚开源的 codis。(twemproxy是twitter开源的一个redis和memcache代理服务器,只用于作为简单的代理中间件,目前twitter内部已经不再使用)
优点: 业务程序端只需要使用普通的api去访问代理程序即可。各种组件分离,以后升级较为容易。也避免了客户端需要维持和每个redis实例的长连接导致连接数过多。
缺点: 增加了一层中间件,增加了网络和数据处理的消耗,性能下降。
Official Redis Cluster
Redis3.0之后的版本开始正式支持 redis cluster,核心目标是:
- **性能:**Redis作者比较看重性能,增加集群不能对性能有较大影响,所以Redis采用了P2P而非Proxy方式、异步复制、客户端重定向等设计,而牺牲了部分的一致性、使用性。
- **水平扩展:**官方文档中称目标是能线性扩展到1000结点。
- **可用性:**集群具有了以前Sentinel的监控和自动Failover能力。
基于twemproxy的redis集群环境
整体架构图

twemproxy的特点
- 支持失败的节点自动摘除(仅作为缓存时)
- 所有的key通过一致性哈希算法分布到集群中所有的redis实例中
- 代理与每个redis实例维持长连接,减少客户端和redis实例的连接数
- 代理是无状态的,可以任意部署多套,避免单点问题
- 默认启用pipeline,连接复用,提高效率,性能损失在 10% - 20%
集群组件
由于twemproxy本身只是简单的代理,所以需要依赖于一些其他的程序组件。
Redis Sentinel: 管理主从备份,用于主从切换,当主服务器挂掉后,自动将从服务器提升为主服务器
Redis-Twemproxy Agent: nodejs写的一个监控程序,用于监听 redis-sentinel 的 master 切换事件,并且及时更新twemproxy的配置文件后将其重新启动
Why not Twemproxy
- 虽然使用 c 开发,性能损失较小,但同样是单线程。所以基本上twemproxy的数量需要和后端redis实例一样甚至更多才能充分发挥多实例的并发能力,造成运维困难。
- twemproxy更改配置文件需要重新启动,比较坑,需要修改代码使其支持动态加载。
- 无法动态扩容,如果需要实现这个功能,要么自己写迁移脚本,手动迁移,比较繁琐,还会影响到当前服务的正常运行。或者二次开发,增加对zookeeper的依赖,将redis节点信息以及hash域相关的数据存储在zookeeper上,然后增加动态迁移数据的模块,可以在不影响现有服务运行的情况下完成增删实例。
Redis Cluster
数据分布:预分片
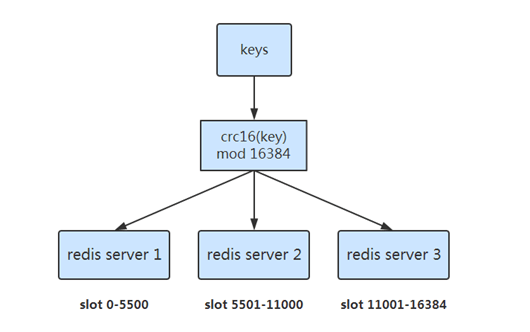
- 预先分配好 16384 个slot
- slot 和 server 的映射关系存储每一个 server 的路由表中
- 根据 CRC16(key) mod 16384 的值,决定将一个key放到哪一个slot中
- 数据迁移时就是调整 slot 的分布
架构:去中心化
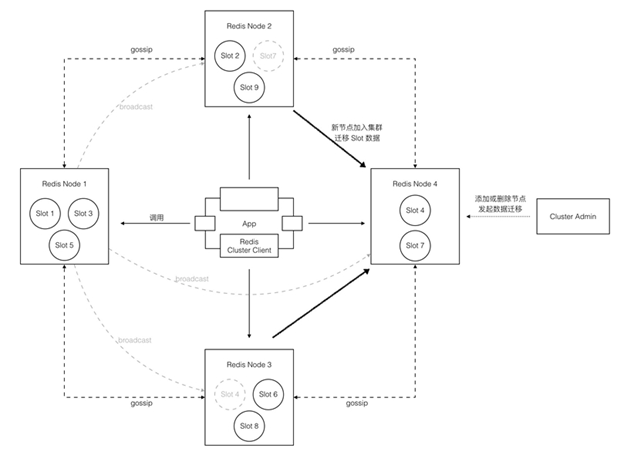
- 无中心结构,每个节点都保存数据和整个集群的状态。
- 采用 gossip 协议传播信息以及发现新节点(最终一致性)。
- 每个节点都和其他所有节点连接,并保持活跃。
- PING/PONG:心跳,附加上自己以及一些其他节点数据,每个节点每秒随机PING几个节点。会选择那些超过cluster-node-timeout一半的时间还未PING过或未收到PONG的节点。
- UPDATE消息:计数戳,如果收到server的计数为3,自己的为4,则发UPDATE更新对方路由表,反之更新自己的路由表,最终集群路由状态会和计数戳最大的实例一样。
- 如果 cluster-node-timeout 设置较小,或者节点较多,数据传输量将比较可观。
- Broadcast:有状态变动时先broadcast,后PING; 发布/订阅。
- Redis node 不作为client请求的代理(不转发请求),client根据node返回的错误信息重定向请求?(需要 smart-client 支持),所以client连接集群中任意一个节点都可以。
可用性:Master-Slave
- 每个Redis Node可以有一个或者多个Slave,当Master挂掉时,选举一个Slave形成新的Master。
- Master Slave 之间异步复制(可能会丢数据)。
- 采用 gossip 协议探测其他节点存活状态,超过 cluster-node-timeout,标记为 PFAIL,PING中附加此数据。当 Node A发现半数以上master将失效节点标记为PFAIL,将其标记为FAIL,broadcast FAIL。
- 各 slave 等待一个随机时间后 发起选举,向其他 master broadcast,半数以上同意则赢得选举否则发起下一次选举
- 当 slave 成为 master,先broadcast,后持续PING,最终集群实例都获知此消息
存在的问题
- Gossip协议通信开销
- 严重依赖于smart-client的成熟度
- 如果smart-client支持缓存slot路由,需要额外占用内存空间,为了效率需要建立和所有 redis server 的长连接(每一个使用该库的程序都需要建立这么多连接)。
- 如果不支持缓存路由信息,会先访问任意一台 redis server,之后重定向到新的节点。
- 需要更新当前所有的client。
- 官方只提供了一个ruby程序 redis-trib 完成集群的所有操作,缺乏监控管理工具,很难清楚目前集群的状态
- 数据迁移以Key为单位,速度较慢
- 某些操作不支持,MultiOp和Pipeline都被限定在命令中的所有Key必须都在同一Slot内
Codis
What is Codis ?
Go语言开发的分布式 Redis 解决方案,对于上层的应用来说,访问 codis 和原生的 redis server 没有明显区别(不支持发布订阅等某些命令,支持 pipeline)。

Codis由四部分组成:
- Codis Proxy (codis-proxy)
- Codis Dashboard (codis-config)
- Codis Redis (codis-server)
- ZooKeeper/Etcd
codis-proxy 是客户端连接的 Redis 代理服务, codis-proxy 本身实现了 Redis 协议, 表现得和一个原生的 Redis 没什么区别 (就像 Twemproxy), 对于一个业务来说, 可以部署多个 codis-proxy, codis-proxy 本身是无状态的。
codis-config 是 Codis 的管理工具, 支持包括, 添加/删除 Redis 节点, 添加/删除 Proxy 节点, 发起数据迁移等操作. codis-config 本身还自带了一个 http server, 会启动一个 dashboard, 用户可以直接在浏览器上观察 Codis 集群的运行状态。
codis-server 是 Codis 项目维护的一个 Redis 分支, 基于 2.8.21 开发, 加入了 slot 的支持和原子的数据迁移指令. Codis 上层的 codis-proxy 和 codis-config 只能和这个版本的 Redis 交互才能正常运行。
Codis 依赖 ZooKeeper 来存放数据路由表和 codis-proxy 节点的元信息, codis-config 发起的命令都会通过 ZooKeeper 同步到各个存活的 codis-proxy。
Codis 支持按照 Namespace 区分不同的产品, 拥有不同的 product name 的产品, 各项配置都不会冲突。
整体设计
- 预分片,1024 slot, key => crc32(key)%1024
- proxy无状态,便于负载均衡,启动时在 Zookeeper 上注册一个临时节点,方便做 HA
- Redis 只作为存储引擎
- Go语言开发,可以充分利用多核,不必像 twemproxy 一样部署很多套
- 性能损失,在不开启pipeline的情况下会损失大概40%,通过加实例线性扩展