最近发现很多数据库都使用了 LSM Tree 的存储模型,包括 LevelDB,HBase,Google BigTable,Cassandra,InfluxDB 等。之前还没有留意这么设计的原因,最近调研时间序列数据库的时候才发现这样设计的优势所在,所以重新又复习了一遍 LSM Tree 的原理。
特点
总的来说就是通过将大量的随机写转换为顺序写,从而极大地提升了数据写入的性能,虽然与此同时牺牲了部分读的性能。
只适合存储 key 值有序且写入大于读取的数据,或者读取操作通常是 key 值连续的数据。
存储模型
WAL
在设计数据库的时候经常被使用,当插入一条数据时,数据先顺序写入 WAL 文件中,之后插入到内存中的 MemTable 中。这样就保证了数据的持久化,不会丢失数据,并且都是顺序写,速度很快。当程序挂掉重启时,可以从 WAL 文件中重新恢复内存中的 MemTable。
MemTable
MemTable 对应的就是 WAL 文件,是该文件内容在内存中的存储结构,通常用 SkipList 来实现。MemTable 提供了 k-v 数据的写入、删除以及读取的操作接口。其内部将 k-v 对按照 key 值有序存储,这样方便之后快速序列化到 SSTable 文件中,仍然保持数据的有序性。
Immutable Memtable
顾名思义,Immutable Memtable 就是在内存中只读的 MemTable,由于内存是有限的,通常我们会设置一个阀值,当 MemTable 占用的内存达到阀值后就自动转换为 Immutable Memtable,Immutable Memtable 和 MemTable 的区别就是它是只读的,系统此时会生成新的 MemTable 供写操作继续写入。
之所以要使用 Immutable Memtable,就是为了避免将 MemTable 中的内容序列化到磁盘中时会阻塞写操作。
SSTable

SSTable 就是 MemTable 中的数据在磁盘上的有序存储,其内部数据是根据 key 从小到大排列的。通常为了加快查找的速度,需要在 SSTable 中加入数据索引,可以快读定位到指定的 k-v 数据。
SSTable 通常采用的分级的结构,例如 LevelDB 中就是如此。MemTable 中的数据达到指定阀值后会在 Level 0 层创建一个新的 SSTable。当某个 Level 下的文件数超过一定值后,就会将这个 Level 下的一个 SSTable 文件和更高一级的 SSTable 文件合并,由于 SSTable 中的 k-v 数据都是有序的,相当于是一个多路归并排序,所以合并操作相当快速,最终生成一个新的 SSTable 文件,将旧的文件删除,这样就完成了一次合并过程。
常用操作的实现
写入
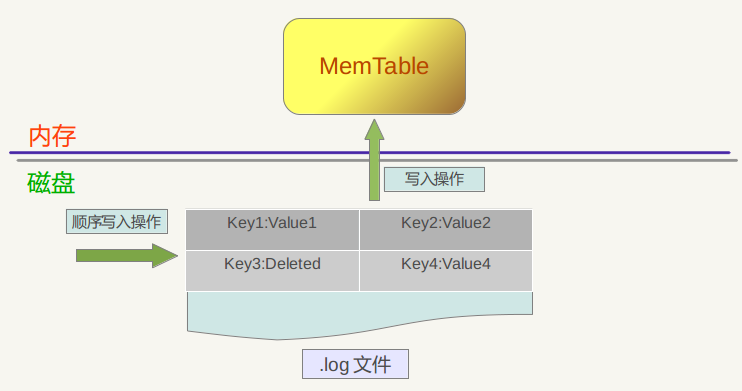
在 LSM Tree 中,写入操作是相当快速的,只需要在 WAL 文件中顺序写入当次操作的内容,成功之后将该 k-v 数据写入 MemTable 中即可。尽管做了一次磁盘 IO,但是由于是顺序追加写入操作,效率相对来说很高,并不会导致写入速度的降低。数据写入 MemTable 中其实就是往 SkipList 中插入一条数据,过程也相当简单快速。
更新
更新操作其实并不真正存在,和写入一个 k-v 数据没有什么不同,只是在读取的时候,会从 Level0 层的 SSTable 文件开始查找数据,数据在低层的 SSTable 文件中必然比高层的文件中要新,所以总能读取到最新的那条数据。也就是说此时在整个 LSM Tree 中可能会同时存在多个 key 值相同的数据,只有在之后合并 SSTable 文件的时候,才会将旧的值删除。
删除
删除一条记录的操作比较特殊,并不立即将数据从文件中删除,而是记录下对这个 key 的删除操作标记,同插入操作相同,插入操作插入的是 k-v 值,而删除操作插入的是 k-del 标记,只有当合并 SSTable 文件时才会真正的删除。
Compaction
当数据不断从 Immutable Memtable 序列化到磁盘上的 SSTable 文件中时,SSTable 文件的数量就不断增加,而且其中可能有很多更新和删除操作并不立即对文件进行操作,而只是存储一个操作记录,这就造成了整个 LSM Tree 中可能有大量相同 key 值的数据,占据了磁盘空间。
为了节省磁盘空间占用,控制 SSTable 文件数量,需要将多个 SSTable 文件进行合并,生成一个新的 SSTable 文件。比如说有 5 个 10 行的 SSTable 文件要合并成 1 个 50 行的 SSTable 文件,但是其中可能有 key 值重复的数据,我们只需要保留其中最新的一条即可,这个时候新生成的 SSTable 可能只有 40 行记录。
通常在使用过程中我们采用分级合并的方法,其特点如下:
- 每一层都包含大量 SSTable 文件,key 值范围不重复,这样查询操作只需要查询这一层的一个文件即可。(第一层比较特殊,key 值可能落在多个文件中,并不适用于此特性)
- 当一层的文件达到指定数量后,其中的一个文件会被合并进入上一层的文件中。
读取

LSM Tree 的读取效率并不高,当需要读取指定 key 的数据时,先在内存中的 MemTable 和 Immutable MemTable 中查找,如果没有找到,则继续从 Level 0 层开始,找不到就从更高层的 SSTable 文件中查找,如果查找失败,说明整个 LSM Tree 中都不存在这个 key 的数据。如果中间在任何一个地方找到这个 key 的数据,那么按照这个路径找到的数据都是最新的。
在每一层的 SSTable 文件的 key 值范围是不重复的,所以只需要查找其中一个 SSTable 文件即可确定指定 key 的数据是否存在于这一层中。Level 0 层比较特殊,因为数据是 Immutable MemTable 直接写入此层的,所以 Level 0 层的 SSTable 文件的 key 值范围可能存在重复,查找数据时有可能需要查找多个文件。
优化读取
因为这样的读取效率非常差,通常会进行一些优化,例如 LevelDB 中的 Mainfest 文件,这个文件记录了 SSTable 文件的一些关键信息,例如 Level 层数,文件名,最小 key 值,最大 key 值等,这个文件通常不会太大,可以放入内存中,可以帮助快速定位到要查询的 SSTable 文件,避免频繁读取。
另外一个经常使用的方法是布隆解析器(Bloom filter),布隆解析器是一个使用内存判断文件是否包含一个关键字的有效方法。
总结
LSM Tree 的思想非常实用,将随机写转换为顺序写来大幅提高写入操作的性能,但是牺牲了部分读的性能。
由于时间序列数据库的特性,运用 LSM Tree 的算法非常合适。持续写入数据量大,数据和时间相关,编码到 key 值中很容易使 key 值有序。读取操作相对来说较少,而且通常不是读取单个 key 的值,而是一段时间范围内的数据,这样就把 LSM Tree 读取性能差的劣势缩小了,反而由于数据在 SSTable 中是按照 key 值顺序排列,读取大块连续的数据时效率也很高。