公司 mesos 集群某个 app 已经有数千的实例数,每次做滚动升级时,由于总资源不足,需要分批操作,每次起一批新版本实例,再停一批旧版本实例。目前停容器的策略是,先从服务发现中摘除需要停掉的节点,等待 60 秒后再停止容器,释放资源,但是实际上每次从发送停止容器的请求到容器资源被实际释放需要长达 6 分钟,导致滚动升级耗时过长。经过排查,最终确认问题出在我们使用 docker 的方式上,这里记录下分析和解决问题的过程。
集群环境
- ubuntu 14.04
- mesos 1.0.1
- docker 1.12.1
现象
从发送停止容器请求给 mesos 调度器到实际资源被释放,耗时超过 6 分钟。登录机器手动调用 docker stop 停止容器只需 10 秒。
排查问题
停止一个容器的请求,经过的步骤如下:
- client 发送停止容器请求给 scheduler。
- scheduler 和 mesos-master 交互,请求停止对应的 TASK。
- mesos-master 发送请求给对应机器的 mesos-agent 要求停止这个容器。
- mesos-agent 发送
TASK_KILL消息给对应的 executor(这里用的是 mesos-docker-executor)。 - mesos-docker-executor 收到
TASK_KILL消息,调用 docker stop 停止容器,确认容器被停止后,发送确认消息给 mesos-agent。 - mesos-docker-executor 退出。
其中步骤二 scheduler 和 mesos-master 的交互会延迟 60s,是为了让容器平滑的关闭,处理完已经接收到的请求。
初步推测可能是 mesos-agent 或者 mesos-docker-executor 组件哪里出现了问题。
检查是否是 mesos-agent 或 executor 的问题
登录要停止的容器的机器,通过 docker ps 查看对应容器的 name,这里假设是 mesos-5ff75923-a2fd-4959-bb3b-4b128e43e9eb-S353.d008ad6c-37be-4cc5-ae40-3ba6a7ebca20。
通过 ps -ef|grep mesos-5ff75923-a2fd-4959-bb3b-4b128e43e9eb-S353.d008ad6c-37be-4cc5-ae40-3ba6a7ebca20 获取这个容器对应的 mesos-docker-executor 的 pid,这里假设是 24235。
通过 ss -antp|grep 24235|grep LIS 查看这个进程目前监听的端口,mesos-agent 会通过这个端口和 mesos-docker-executor 通信,我们需要使用 tcpdump 抓包跟踪这两个组件之间的通信,这里假设端口为 20017。
抓包命令 tcpdump -i any -ASnn port 20017
结果如下:
00:39:22.202763 IP 192.168.76.53.21877 > 192.168.76.53.20017: Flags [P.], seq 3399346312:3399346653, ack 3564212561, win 342, length 341
E..}..@.@.<...L5..L5UuN1.....q.QP..V.+..POST /executor(1)/mesos.internal.KillTaskMessage HTTP/1.1
User-Agent: libprocess/slave(1)@192.168.76.53:5051
Libprocess-From: slave(1)@192.168.76.53:5051
Connection: Keep-Alive
Host:
Transfer-Encoding: chunked
6f
+
)5ff75923-a2fd-4959-bb3b-4b128e43e9eb-0000.@
>image.cb5aeece-697b-11e7-ad61-6c92bf2f06d8.1500136612181605046
0
00:44:22.516118 IP 192.168.76.53.21877 > 192.168.76.53.20017: Flags [P.], seq 3399346994:3399347417, ack 3564212561, win 342, length 423
E.....@.@.<...L5..L5UuN1...2.q.QP..V.}..POST /executor(1)/mesos.internal.StatusUpdateAcknowledgementMessage HTTP/1.1
User-Agent: libprocess/slave(1)@192.168.76.53:5051
Libprocess-From: slave(1)@192.168.76.53:5051
Connection: Keep-Alive
Host:
Transfer-Encoding: chunked
ae
+
)5ff75923-a2fd-4959-bb3b-4b128e43e9eb-S353.+
)5ff75923-a2fd-4959-bb3b-4b128e43e9eb-0000.@
>image.cb5aeece-697b-11e7-ad61-6c92bf2f06d8.1500136612181605046"..!....Hn.'.j&.6.
0
00:44:22.516137 IP 192.168.76.53.20017 > 192.168.76.53.21877: Flags [.], ack 3399347417, win 2523, length 0
E..(..@.@.u...L5..L5N1Uu.q.Q....P. .....
00:44:23.486916 IP 192.168.76.53.20017 > 192.168.76.53.21877: Flags [F.], seq 3564212561, ack 3399347417, win 2523, length 0
E..(..@.@.u...L5..L5N1Uu.q.Q....P. .....
00:44:23.487507 IP 192.168.76.53.21877 > 192.168.76.53.20017: Flags [F.], seq 3399347417, ack 3564212562, win 342, length 0
查看 meso-agent 日志如下:
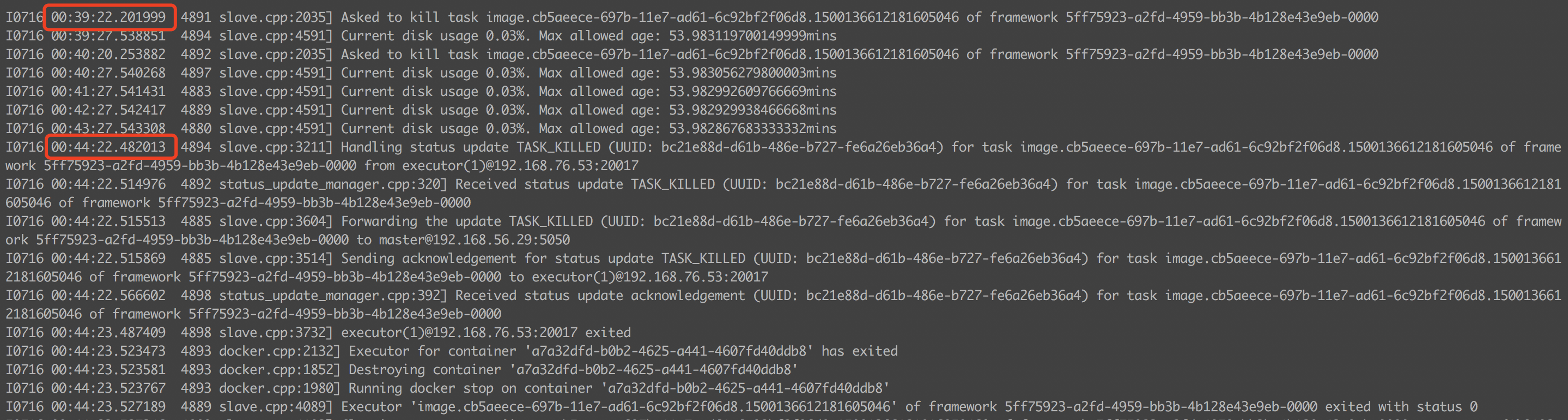
确认 mesos-agent 在 00:39:22 给 mesos-docker-executor 发送了 kill task 的消息,但是 mesos-docker-executor 在 00:44:22 时才回复消息确认实例被停止了。
说明问题出在 mesos-docker-executor。
分析 mesos-docker-executor 源码

可以看出,这里有一个很关键的 gracePeriod 变量,如果停止任务的请求中有设置 killPolicy 则此值为 killPolicy 中的值,否则使用默认值。
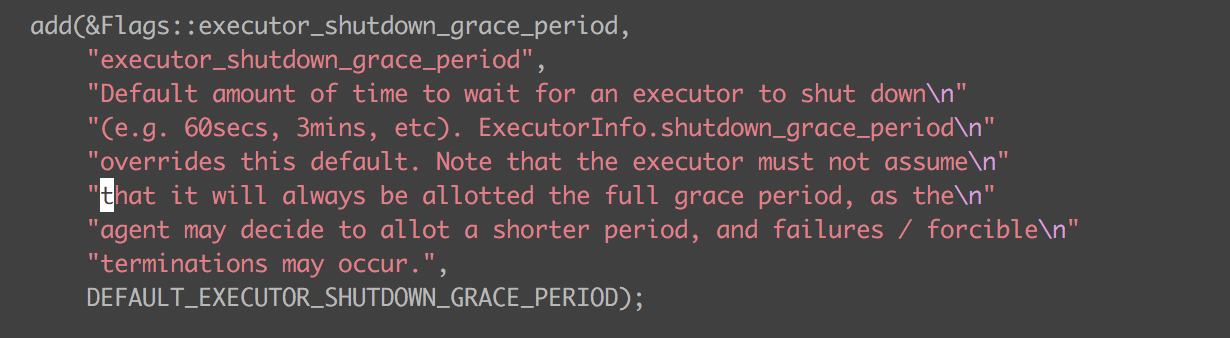
这个值在 mesos-agent 启动的时候通过 --executor_shutdown_grace_period 传进去,实际环境中我们配置的是 5 分钟。
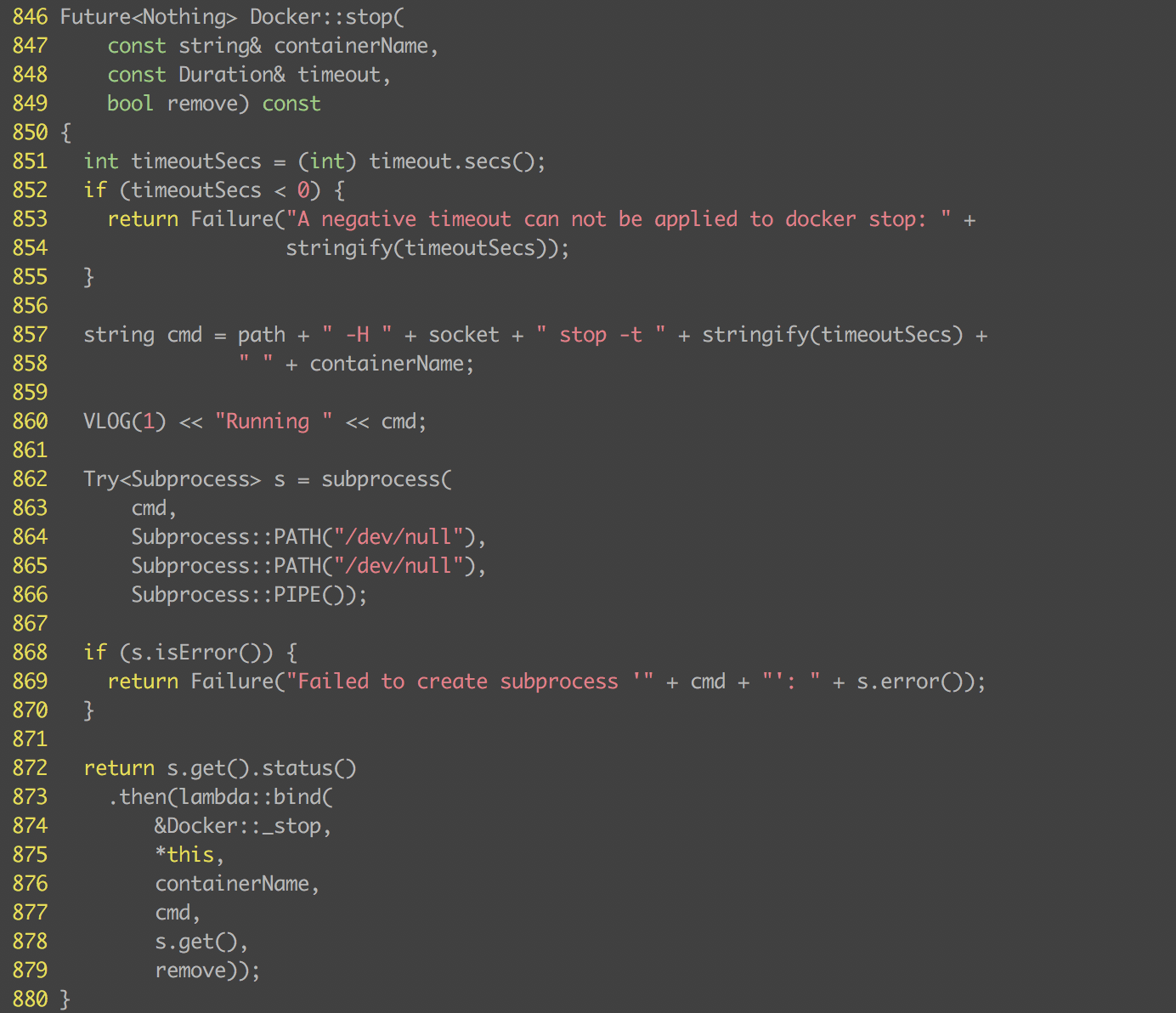
mesos-docker-executor 会根据 gracePeriod 的值调用 docker stop -t 来停止容器。
docker 问题排查
docker stop 停止一个容器会先发送 SIGTERM 信号给容器,如果在 -t 指定的时间仍然没有结束,则发送 SIGKILL 信号强行杀掉。所以问题就是为什么我们的容器收到 SIGTERM 信号后没有退出。
使用 docker exec -ti {container_name} bash 登录容器,查看容器内进程:
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 00:04 ? 00:00:00 /bin/sh /root/start.sh
root 8 1 99 00:04 ? 01:25:14 /root/dora-image -f /root/doraimage.conf
root 1111 0 2 01:23 ? 00:00:00 bash
root 1216 1111 0 01:23 ? 00:00:00 ps -ef
手动向 PID 为 1 的进程发送 SIGTERM 信号,结果无响应,到这一步已经定位到问题所在了。
通过 Google 搜索后了解到原因。
如果 pid 为 1 的进程,无法向其子进程传递信号,可能导致容器发送 SIGTERM 信号之后,父进程等待子进程退出。此时,如果父进程不能将信号传递到子进程,则整个容器就将无法正常退出,除非向父进程发送 SIGKILL 信号,使其强行退出。
考虑如下进程树:
- bash(PID 1)
- app(PID2)
bash 进程在接受到 SIGTERM 信号的时候,不会向 app 进程传递这个信号,这会导致 app 进程仍然不会退出。对于传统 Linux 系统(bash 进程 PID 不为 1),在 bash进程退出之后,app进程的父进程会被 init 进程(PID 为 1)接管,成为其父进程。但是在容器环境中,这样的行为会使 app 进程失去父进程,因此 bash 进程不会退出。
解决方案
最后找到了一个解决 init 问题的项目 tini。而对于我们遇到的问题,目前想到的解决方案有三个:
- docker 1.13 及以后的版本已经解决了 init 问题,就是内置了 tini,使 tini 作为 PID 为 1 的进程启动。
- 升级 docker 版本难度较大,既然明确了新版本 docker 是如何解决问题的,我们就直接使用 tini 作为 init 进程即可。
- 修改 mesos-agent 的启动参数,将
executor_shutdown_grace_period设置的短一些,但是这样会影响到其他正常的容器。
经过考虑,采用方案二较为简单和稳妥。
总结
对于 mesos 和 docker 的使用姿势还不熟悉,并且这两个项目的生态系统也并不成熟,导致在实际使用的过程中容易遇到各种各样的问题。通过日志,抓包,源码分析等手段相结合,就能够快速地定位到问题,再通过搜索引擎和官方文档资料等来解决问题。如果是一些社区当前还没有解决的问题,可能需要自己修改源码来 fix。