测试环境发现 istiod 有持续的 Push 时间较长的问题。
问题
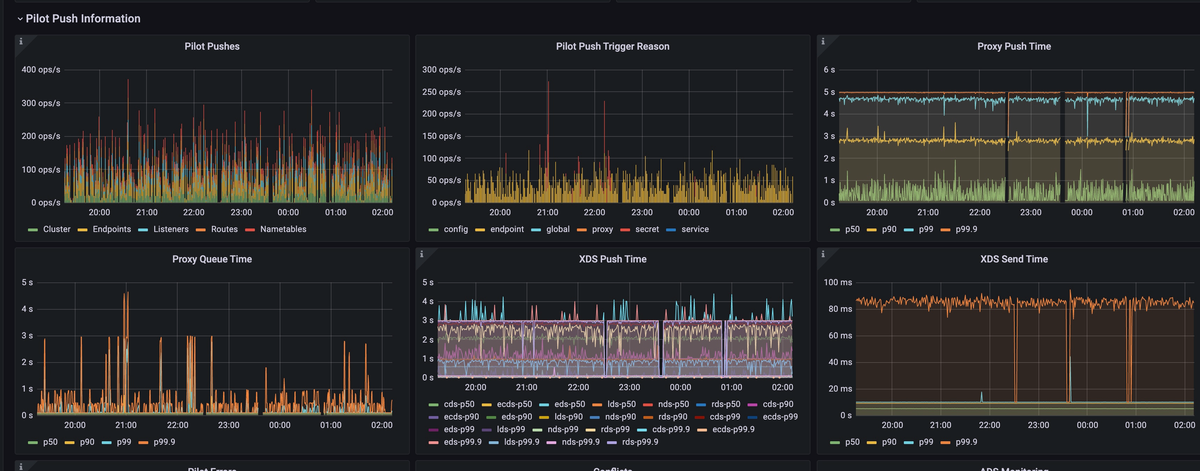
Push 耗时的 99 值接近 5s。其中 TriggerReason 大部分是 endpoint。
查询 istiod pod 的日志,发现当时有较多的如下日志:
info ads Incremental push, service {service name} at shard Kubernetes/Kubernetes has no endpoints
info ads Push debounce stable[34060] 1 for config ServiceEntry/{namespace}/{service name}: 100.318346ms since last change, 100.318141ms since last push, full=false
info ads Full push, service accounts changed, {service name}
info ads Push debounce stable[34061] 1 for config ServiceEntry/{namespace}/{service name}: 100.687724ms since last change, 100.687555ms since last push, full=true
分析
通过查看当时日志中对应实例的情况,确认问题的原因是由于这个服务只有一个 pod,且由于服务不稳定,会频繁地在 Ready 和 UnReady 之间变化。
这些变化触发了 istio 控制面的逻辑,认为服务的 service accounts 发生了变化,从而触发了一次 Full Push。正常来说,如果只有 endpoint ip 变化的话,istio 会采用 Incremental push,不怎么耗费资源,推送也会很快。
这个行为的逻辑在不同 Istio 版本中也有一些差异:
Istio 1.13
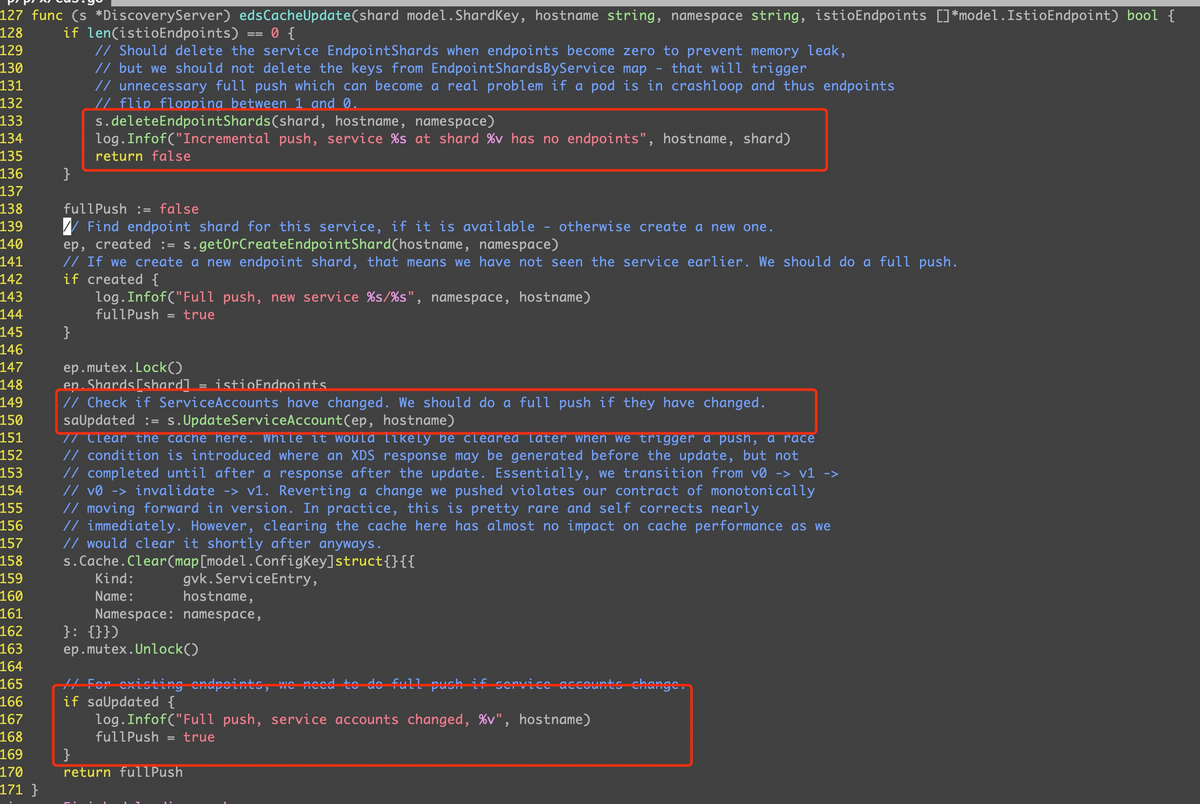
1.13 以及之前的版本,会在 istiod cache 中记录 endpoints 对应的 service accounts,业务服务一般默认都是 default。
当 endpoints 中的 address 都被删除,没有 ready 的实例之后,istiod 会 watch 到这个变化,然后先在 cache 中将对应的 endpoints 删除,并且 service accounts name 也会被删除。
而当这个 pod 恢复,endpoints 的 address 中又有了这个 ip 之后,istiod 会从对应的 pod spec 中拿到其 service accounts name,再加到 cache 中。之后会去做判断,如果 service accounts name 发生了变化,就会触发一次 Full Push,否则就用 Incremental push。由于 service accounts name 之前被删除了,所以这里肯定会被判断为出现了变化,从而走 Full Push 的逻辑。
所以当一个服务正常扩缩容时,是 Incremental push,成本很低,推送延迟也很低。但是当服务的 endpoints 的 ip 数量从 0 变成非 0 时,就会触发一次 Full Push。
Istio 1.14
1.14 这个版本支持了流量预热,且为了更好地支持这个功能,istiod 新增了一个环境变量,PILOT_SEND_UNHEALTHY_ENDPOINTS,这个变量为 true 时,istiod 会将 K8s endpoints 中 UnReady 的 addresses 也发送给 envoy,但是标记 status 为 unhealthy,正常情况下 envoy 是不会将流量路由到 unhealthy 的实例。
1.14.0 中这个变量值默认是 true,但是后来有人发现出现了一些异常情况,比如当一个服务下所有 pod 不健康之后,会触发 envoy 的 panic threshold,导致流量仍然会被路由到不健康的实例上,这不符个 K8s 中 UnReady 的语义。
所以为了避免这个问题,在 1.14.2 中,将 PILOT_SEND_UNHEALTHY_ENDPOINTS 的默认值修改为了 false。但是这样会导致流量预热这个功能出现一些问题(具体原因比较复杂,暂不详细说明)。如果手动配置将 PILOT_SEND_UNHEALTHY_ENDPOINTS 改为 true,则现在会禁用掉 envoy 的 panic threshold 的功能,但是这个功能被 OutlierDetection.minHealthPercent 所使用,所以两个是互斥的。目前还不明确最佳实践是什么样的。
istio 社区给 envoy 提了一个 Issues 在 endpoint 的 healthy 和 unhealthy 之外增加一个状态,这个状态表示即使在 panic threshold 的状态下,也不将流量发给这个状态的实例。
在这个版本中,如果 PILOT_SEND_UNHEALTHY_ENDPOINTS 为 false,则和 1.13 中的逻辑一样会触发 Full Push。
如果 PILOT_SEND_UNHEALTHY_ENDPOINTS 为 true,由于会将 unready 的 address 也计算在内,所以当所有 pod 都 unready 之后,并不会在 cache 中将 service accounts name 移除。当 pod 恢复 ready 之后,也就不会认为是 service accounts name changed,也就不会触发 Full Push。
Istio 1.15
1.15 中,即使 PILOT_SEND_UNHEALTHY_ENDPOINTS 为 false,也不会因为所有 pod 从 unready 变为 ready 而触发 Full Push 了。
具体的代码逻辑还没有细看,1.15 目前在 beta 阶段,也没有详细的 release notes,猜测是和 https://github.com/istio/istio/pull/39133 以及一些 xds delta 推送的优化相关。
结论
当更新到 Istio 1.15 之后,基本上可以忽略这个问题造成的影响。
但是如果一个服务,就是实例数从 0 扩到 1,仍然会触发一次 Full Push。可能的一种情况是,一个服务只有一个 Pod,然后会被频繁的 Evict。这种情况应该比较少见。
更新: 1.15.1 中有一个 PR 进行了优化,实例数缩到 0 再扩到 1 应该也不会触发 Full Push 了。