服务接入 Istio 后,观测到有极少量的 503 错误。
reason 是 upstream_reset_before_response_started{connection_termination},没有什么规律,服务自身状态也正常,未重启。
背景知识
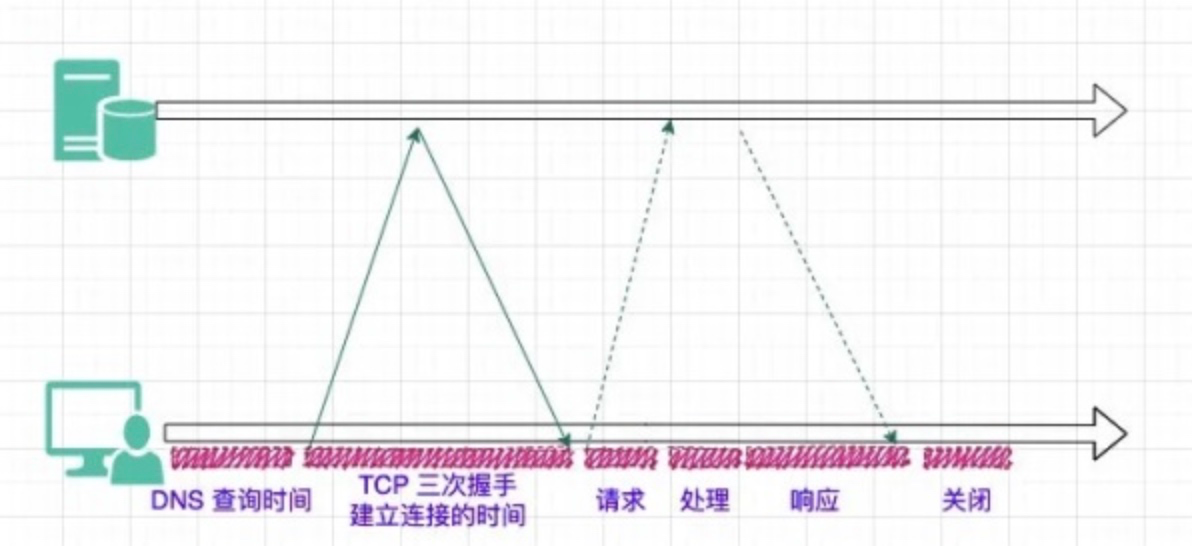
常规的 HTTP1.0 请求,客户端会先建立 TCP 连接,发送请求,接收响应,再关闭连接。
这样会导致每次请求都需要建立新的连接,延迟增加,耗费资源。
所以在 HTTP1.1 中可以通过 KeepAlive 的方式,复用连接,避免频繁创建连接造成的开销。在单个连接中,请求和响应以及多个请求之间仍然是串行的,只有当前一个请求的响应体完全读取完成后,这个连接才可以被复用。
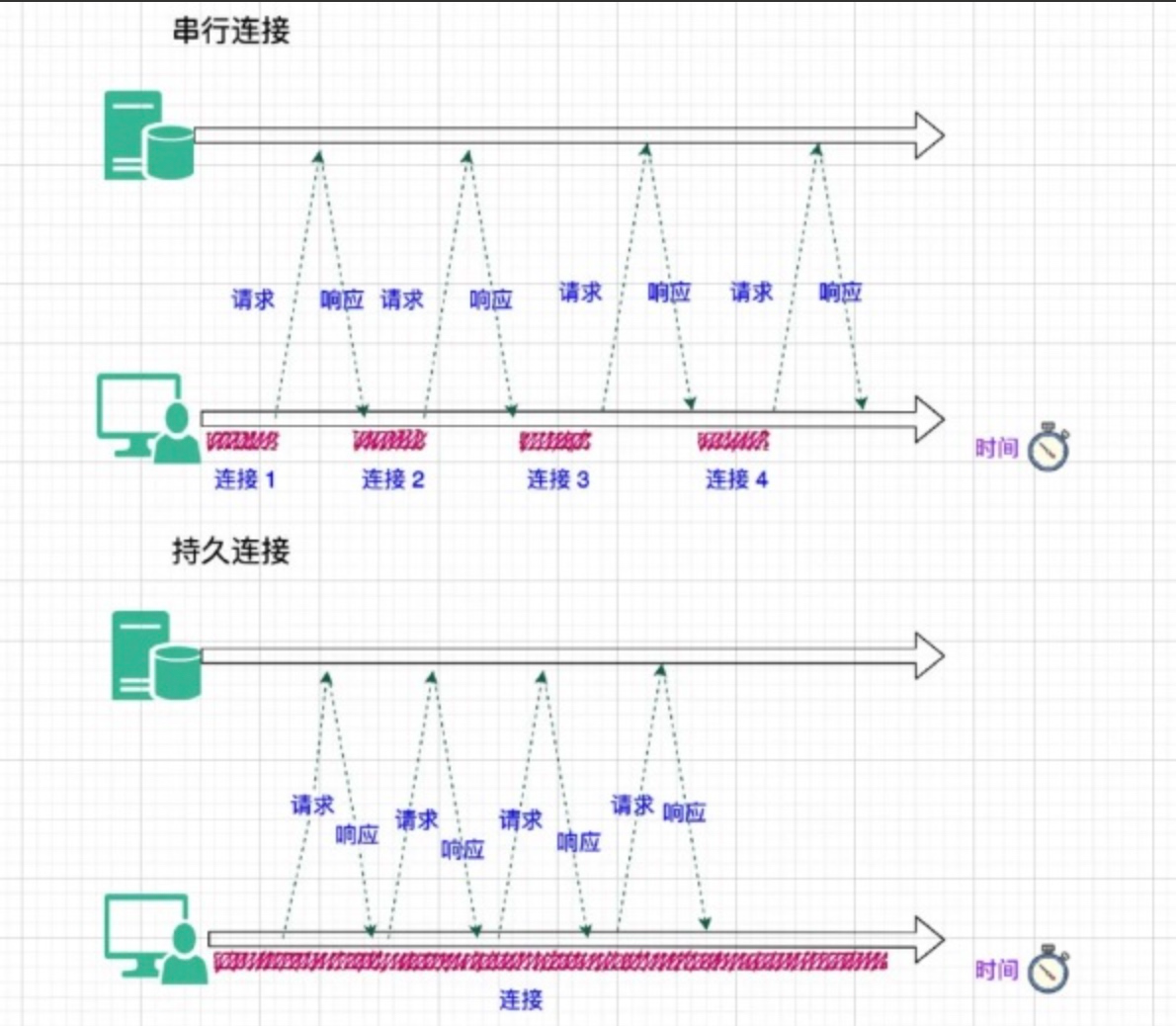
既然存在连接复用,就需要有一套连接管理机制。当需要发起请求时,客户端需要决定什么时候新建连接,什么时候释放长期空闲的连接。
同样,服务端也可以决定什么时候断开空闲的连接。
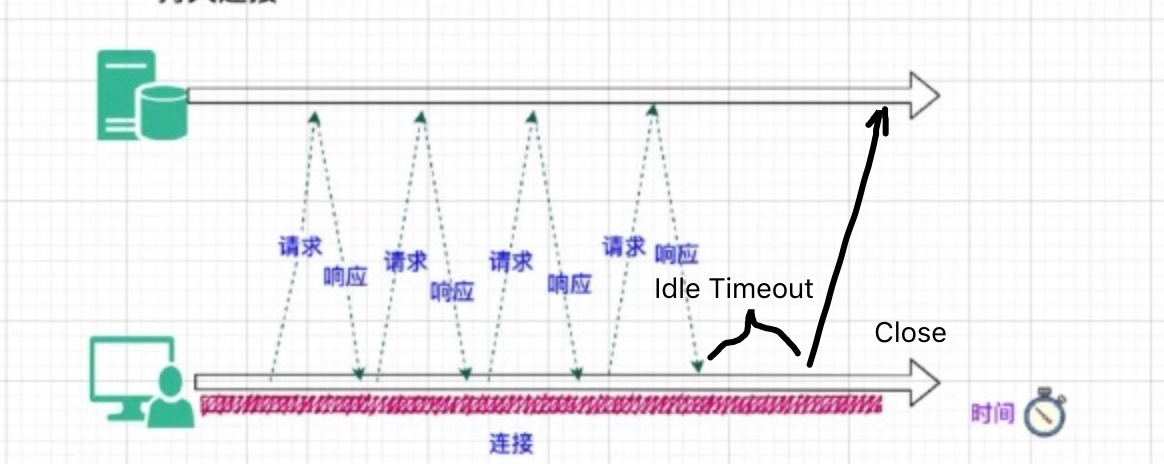
例如当连接上持续一段时间 (Idle Conn Timeout) 都没有请求后,客户端可以断开连接。同样,服务端在连接空闲一段时间后,也可以主动断开连接。
问题原因
我们遇到的问题,就是当服务端的 HTTP IdleConnTimeout 小于客户端的 IdleConnTimeout 时,有偶发的 race condition 的情况。
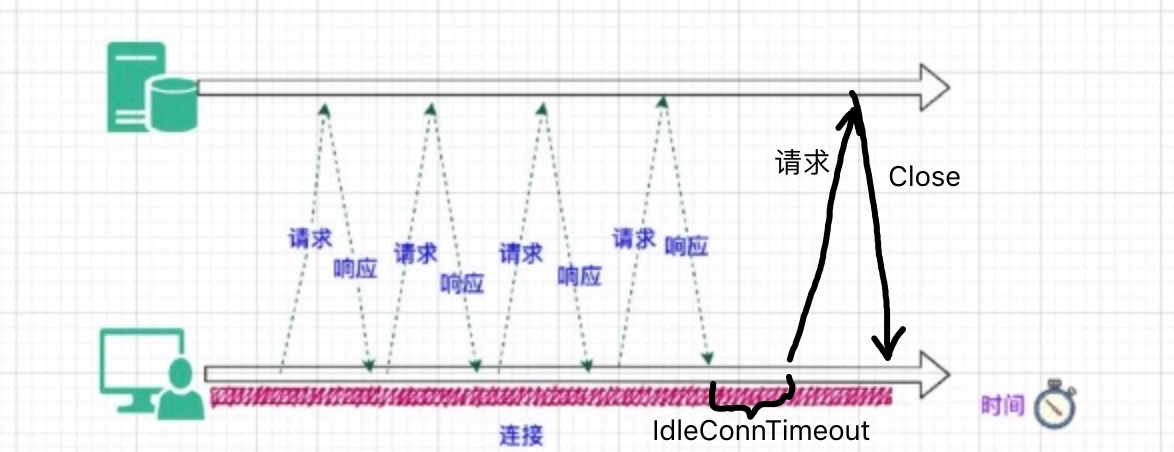
假设客户端的 IdleConnTimeout 是 15s,服务端是 5s。
当前连接空闲接近 5s 时,客户端发送请求到服务端,由于涉及网络通信,相对需要一段时间。此时服务端刚好认为此连接空闲达到 5s,就将连接 Close 掉。客户端收到 Reset 包,请求失败,如果是网关的话,就会返回 502/503。
通过线上日志分析两个服务,服务端设置的 IdleConnTimeout 都是 15s。
其中服务 A 一天的请求量接近 2 亿,有 2 个请求因为此原因返回 503。 服务 B 一天的请求接近 8800 万,有 11 个请求因为此原因返回 503。
当前各种 keepalive 的配置
IngressNginx
keepalive_timeout 同 IdleConnTimeout
keepalive_requests 表示一个连接上最多跑多个个请求后就会被断开,一般用于释放资源,避免资源泄露。
作为 Server 接收请求:
keepalive_timeout 75s
keepalive_requests 100
作为 Client 请求 Upstream:
keepalive_timeout 60s
keepalive_requests 10000
IstioEnovy
出流量:
IdleConnTimeout 3600s
maxRequestsPerConnection 默认无限制
入流量:
有两种方式,一种是连接级别,默认值是 3600s。
一种是通过 cleanup_interval 来配置的,是 host 级别的清理。每 60s 清理一次 host 级别没有活跃请求的所有连接。
解决方案
目前可行的解决方案是缩短客户端的 IdleConnTimeout 或者增加服务端的 IdleConnTimeout,使服务端的超时时间略大于客户端即可,保证由客户端来断开连接,避免出现 race condition 的问题。
Google Cloud Load Balancing 关于自身 keepalive 超时的说明

根据各个网关以及一些语言客户端的 IdleConnTimeout 的配置,推荐:
后端服务作为 HTTP Server 时,设置的 IdleConnTimeout 不小于 120s,从而让客户端断开空闲连接,避免这个问题。
客户端需要明确设置 HTTP Keepalive timeout,推荐根据需要配置 60s 或 90s。