Java 项目,基于 HBase(2.3版本貌似开始支持 Google BigTable 和 Cassandra) 的一个时间序列数据库,被广泛应用于监控系统中。很多大公司都在使用,社区较为活跃。
测试版本
hbase-1.1.5
opentsdb-2.2.0
单机部署
单机部署可以参考我之前的一篇文章,集群部署比较复杂,这里仅使用单机进行测试。
概念
数据格式
- metric: 一个可测量的单位的标称。
- tags: 对 metric 的具体描述。
- timestamp: 时间戳。
- value: metric 的实际测量值。
UID
在 OpenTSDB 中,每一个 metric、tagk 或者 tagv 在创建的时候被分配一个唯一标识叫做 UID。在后续的实际存储中,实际上存储的是 UID,而不是它们原本的字符串,UID 占 3个字节(也可以修改源码改为4字节),这样可以节省存储空间。
TSUID
<metric_UID><timestamp><tagk1_UID><tagv1_UID>[...<tagkN_UID><tagvN_UID>]
写入 HBase 时的 row key 格式,其中的 metric、tagk 和 tagv 都被转换成了 UID。
Data Table Schema
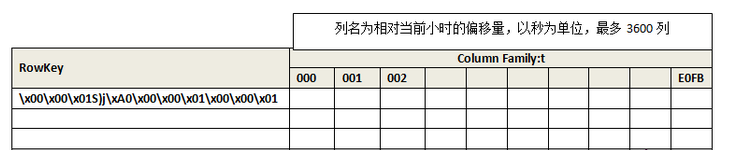
RowKey 就是上述的 TSUID,除了时间戳占 4 byte,其余 UID 占 3 byte。
时间戳的部分只保留到了小时粒度,具体相对于小时的偏移量被存储在了 列族 t 中。这样就减小了 HBase 中的存储行数。也就是说对于同一个小时的 metric + tags 相同的数据都会存放在一个 row 下面,这样的设计提高了 row 的检索速度。
这样的 RowKey 设计使得 metric + tags 相同的数据都会连续存放,且 metric 相同的数据也会连续存放,底层 HBase 中会放在同一 Region 中,在做 Scan 的时候可以快速读取到大片数据,加速查询的过程。
value 使用 8 bytes 存储,既可以存储 long,也可以存储 double。
Compaction
在 OpenTSDB 中,会将多列合并到一列之中以减少磁盘占用空间,这个过程会在 TSD 写数据或者查询过程中不定期的发生。
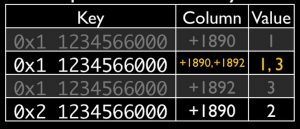
例如图中,将列 1890 和 列 1892 合并到了一起。
API
OpenTSDB 同样提供了一套基于 HTTP 的 API 接口。
插入数据
http://localhost:4242/api/put, POST
内容为 JSON 格式,支持同时插入多条数据。
[
{
"metric": "sys.cpu.nice",
"timestamp": 1346846400,
"value": 18,
"tags": {
"host": "web01",
"dc": "lga"
}
},
{
"metric": "sys.cpu.nice",
"timestamp": 1346846400,
"value": 9,
"tags": {
"host": "web02",
"dc": "lga"
}
}
]
查询数据
http://localhost:4242/api/query, POST
{
"start": 1463452826,
"end": 1463453026,
"globalAnnotations": true,
"queries": [
{
"aggregator": "avg",
"metric": "sys.disk.usage",
"downsample": "60s-avg",
"tags": {
"host_id": "123"
}
},
{
"aggregator": "sum",
"metric": "sys.cpu.load",
"downsample": "60s-avg",
"tags": {
"host_id": "123"
}
}
]
}
start 和 end 指定了查询的时间范围。
tags 指定了过滤条件,2.2 版本中将不被推荐,取而代之的是 filters 参数。
downsample 聚合计算,例如上面是对每隔60s的数据计算一次平均值。
总结
OpenTSDB 在存储时间序列数据这一领域拥有很大的优势,被大多数公司所采用,网上的相关文档也比较全面。
底层存储依托于 HBase,采用特殊设计过的数据存储格式,提供了非常快的查询速度,在此基础之上也更容易横向扩展。
但是,相对于 InfluxDB 这种即使是新手也可以在两分钟内部署运行完成,OpenTSDB 的部署和运维显然要麻烦很多,由于底层依赖于 HBase,想要大规模运行起来,需要相当专业、细心的运维工作。