问题
线上的 Istio 集群,突然出现了 istiod cpu 跑的很高,配置下发延迟大幅增加,甚至 endpoints 的变更出现了一直无法同步的问题,导致部分请求发送到了已经停止的 pod IP 上,返回 503。
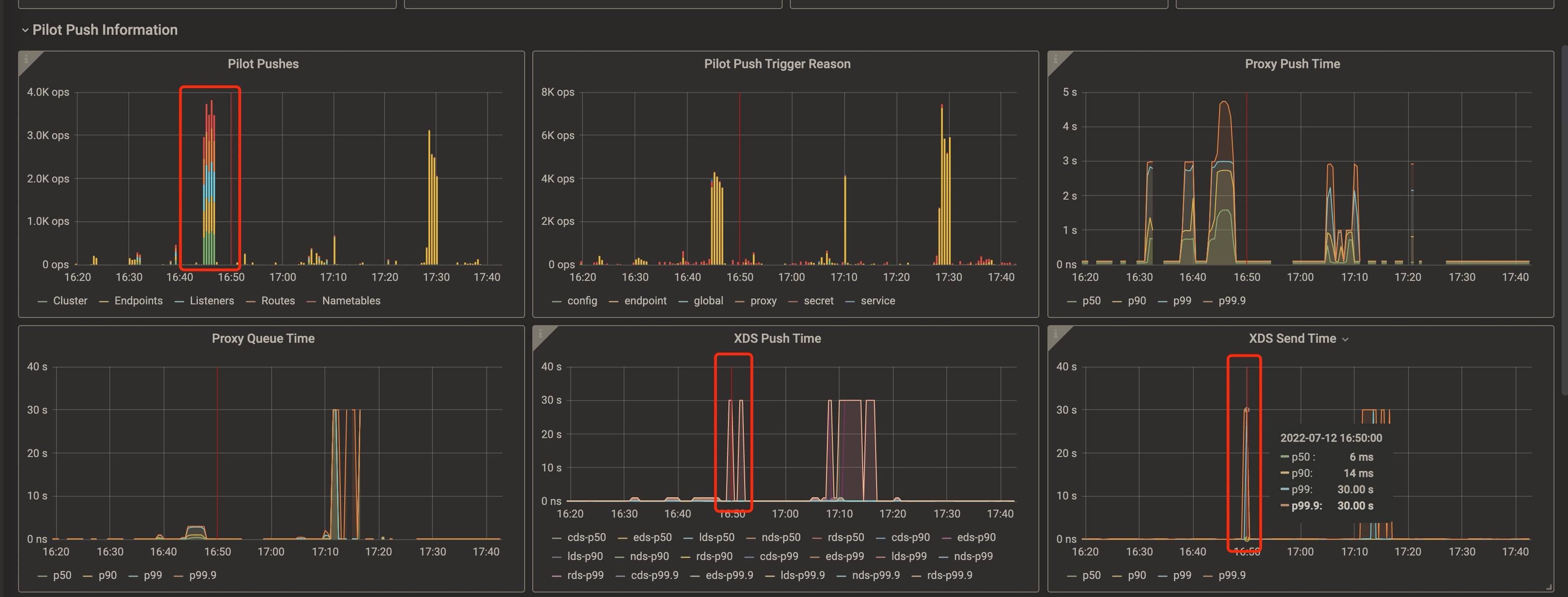
原因
结合当时的发版记录,确认是由于 node-exporter 的更新导致了问题。由于之前简单研究过 headless service 在 Istio 中的实现,所以很快就猜测到了原因。
因为 node-exporter 有一个对应的 headless 的 service,导致 node-exporter 更新时触发了问题。
简要分析
产生这个问题主要是和 Headless Service 在 Istio 中的实现方式有关。
普通的 Service 会分配一个虚拟的 ClusterIP,访问 service name 时,DNS 返回 ClusterIP,连接这个 IP,会由 kube-proxy 做负载均衡,连接到实际的目的 Pod IP。
Headless Service 不会分配 ClusterIP,访问 service name 时,DNS 会返回所有的 Pod IP,由应用决定连接到哪一个 IP。
在 Istio 中,普通的 Service,当服务发版时,只有 Endpoint 变更,ClusterIP 不变。Endpoint 的变更可以以增量的方式进行推送。对应 Istiod 中会有一条 full=false 的推送日志。
而 Headless Service,由于实现问题,在 Istio 中非常的重,每一个对应的 Pod IP,在 envoy 中都会有自己独立的 listener(地址是 pod ip),route 和 cluster。而目前 Istio 的实现中,如果是非 Endpoint 资源的变更,都会触发一次全量推送,对于我们目前的使用方式来说,会向所有的 Pod 做全量推送,对应 Istiod 中会有一条 full=true 的推送日志。(注:这个问题仅限 TCP 端口的服务,如果声明为 HTTP 协议的端口,则逻辑和普通的 Service 比较接近)每一次全量推送都需要大量的计算资源,如果是持续的配置变更,那就可能会把 cpu 持续的跑满。
node-exporter 发版过程中,由于会更新所有节点上的实例,会持续地导致 Istiod 做全量推送,从而将 CPU 跑满。
至于为什么 Istiod 负载下降后,仍然没有将实时的配置正确推送到有问题的 sidecar,尚不明确。猜测大概率是 Istiod 在 CPU 跑满时,某个异常的处理逻辑不完善,导致没有正确地恢复。后续通过重启 Istiod 实例恢复了推送。
解决方案
Headless Service 通过 Istio sidecar 劫持后来做路由的意义不是很大,所以一般可以通过给 Service 添加 networking.istio.io/exportTo: ~ annotation 来让 istio 控制面完全忽略这个 service,就不会渲染相关的配置了。
另外,istiod 还提供了 PILOT_ENABLE_HEADLESS_SERVICE_POD_LISTENERS 这个 feature 控制变量,默认值是 true,如果设置为 false,应该也可以缓解这个问题。但是由于我们不需要 Headless Service 的管理,所以没有测试这个功能,直接忽略掉更简单一些。